Unsupervised quality estimation
This documentation includes instructions for running unsupervised quality estimation, as described in the paper Unsupervised Quality Estimation for Neural Machine Translation (Fomicheva et al., 2020). We check the unsupervised metric with the NLLB model setup used in our experiments.
Requirements
mosesdecoder: https://github.com/moses-smt/mosesdecoder
subword-nmt: https://github.com/rsennrich/subword-nmt
Test data
We test the unsupervised metric on the new ATIH ground truth dataset.
Set-up
Given a test set consisting of source sentences and reference translations:
SRC_LANG: source language
TGT_LANG: target language
INPUT: input prefix, such that the file $INPUT.$SRC_LANG contains source sentences and $INPUT.$TGT_LANG contains the reference sentences
OUTPUT_DIR: output path to store results
MOSES_DECODER: path to mosesdecoder installation
BPE_ROOT: path to subword-nmt installation
BPE: path to BPE model
MODEL_DIR: directory containing the NMT model .pt file as well as the source and target vocabularies.
TMP: directory for intermediate temporary files
GPU: if translating with GPU, id of the GPU to use for inference
DROPOUT_N: number of stochastic forward passes
Our set-up is:
SRC_LANG="en"
TGT_LANG="fr"
IN_DIR="data_2021"
INPUT="new_atih_ground_truth"
OUTPUT_DIR="qe_output"
MOSES_DECODER="mosesdecoder"
BPE_ROOT="subword-nmt"
BPE="../wmt14.en-fr.fconv-py/bpecodes"
MODEL_DIR="../wmt14.en-fr.fconv-py"
MY_MODEL='round_3rd/checkpoint_best.pt:round_4th/checkpoint_best.pt:round_5th/checkpoint_best.pt'
TMP="tmp"
GPU=0
DROPOUT_N=30
SCRIPTS="fairseq/examples/unsupervised_quality_estimation"
Translate the data using standard decoding
## Preprocess the input data
for LANG in $SRC_LANG $TGT_LANG; do
perl $MOSES_DECODER/scripts/tokenizer/tokenizer.perl -threads 80 -a -l $LANG < $INPUT.$LANG > $TMP/preprocessed.tok.$LANG
python $BPE_ROOT/apply_bpe.py -c ${BPE} < $TMP/preprocessed.tok.$LANG > $TMP/preprocessed.tok.bpe.$LANG
done
## Binarize the data for faster translation:
fairseq-preprocess --srcdict $MODEL_DIR/dict.$SRC_LANG.txt --tgtdict $MODEL_DIR/dict.$TGT_LANG.txt --source-lang ${SRC_LANG} --target-lang ${TGT_LANG} --testpref $TMP/preprocessed.tok.bpe --destdir $TMP/bin --workers 4
## Translate
CUDA_VISIBLE_DEVICES=$GPU fairseq-generate $TMP/bin --path ${MODEL_DIR}/${SRC_LANG}-${TGT_LANG}.pt --beam 5 --source-lang $SRC_LANG --target-lang $TGT_LANG --no-progress-bar --unkpen 5 > $TMP/fairseq.out
grep ^H $TMP/fairseq.out | cut -d- -f2- | sort -n | cut -f3- > $TMP/mt.out
## Post-process
sed -r 's/(@@ )| (@@ ?$)//g' < $TMP/mt.out | perl $MOSES_DECODER/scripts/tokenizer/detokenizer.perl
-l $TGT_LANG > $OUTPUT_DIR/mt.out
### Produce uncertainty estimates
#Scoring
#Make temporary files to store the translations repeated N times.
python ${SCRIPTS}/scripts/uncertainty/repeat_lines.py -i $TMP/preprocessed.tok.bpe.$SRC_LANG -n $DROPOUT_N -o $TMP/repeated.$SRC_LANG
python ${SCRIPTS}/scripts/uncertainty/repeat_lines.py -i $TMP/mt.out -n $DROPOUT_N -o $TMP/repeated.$TGT_LANG
fairseq-preprocess --srcdict ${MODEL_DIR}/dict.${SRC_LANG}.txt $TGT_DIC --source-lang ${SRC_LANG} --target-lang ${TGT_LANG} --testpref ${TMP}/repeated --destdir ${TMP}/bin-repeated
## Produce model scores for the generated translations using --retain-dropout option to apply dropout at inference time:
CUDA_VISIBLE_DEVICES=${GPU} fairseq-generate ${TMP}/bin-repeated --path ${MODEL_DIR}/${LP}.pt --beam 5 --source-lang $SRC_LANG --target-lang $TGT_LANG --no-progress-bar --unkpen 5 --score-reference --retain-dropout --retain-dropout-modules '["TransformerModel","TransformerEncoder","TransformerDecoder","TransformerEncoderLayer"]' TransformerDecoderLayer --seed 46 > $TMP/dropout.scoring.out
grep ^H $TMP/dropout.scoring.out | cut -d- -f2- | sort -n | cut -f2 > $TMP/dropout.scores
## Compute the mean of the resulting output distribution:
python $SCRIPTS/scripts/uncertainty/aggregate_scores.py -i $TMP/dropout.scores -o $OUTPUT_DIR/dropout.scores.mean -n $DROPOUT_N
Results
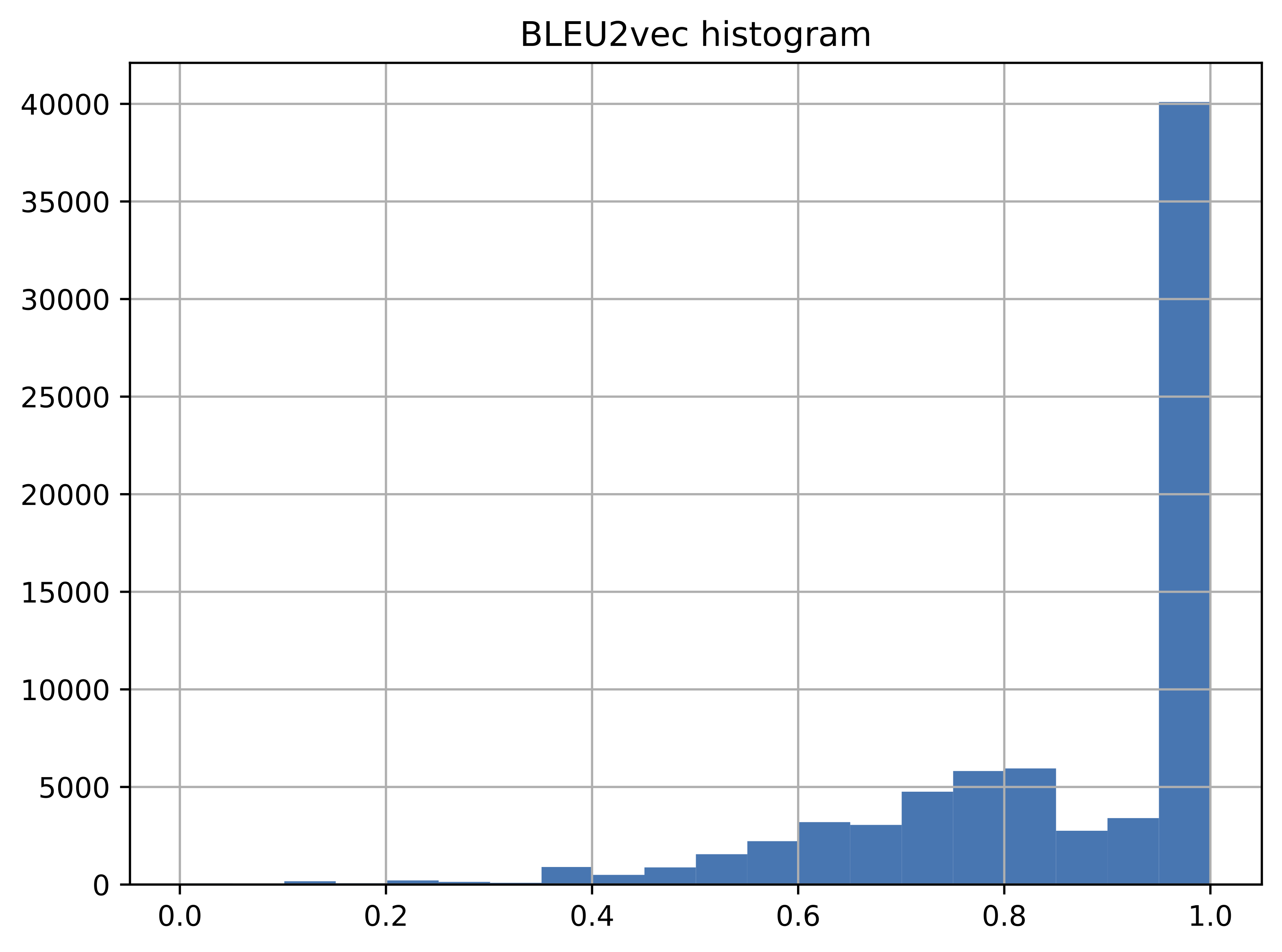
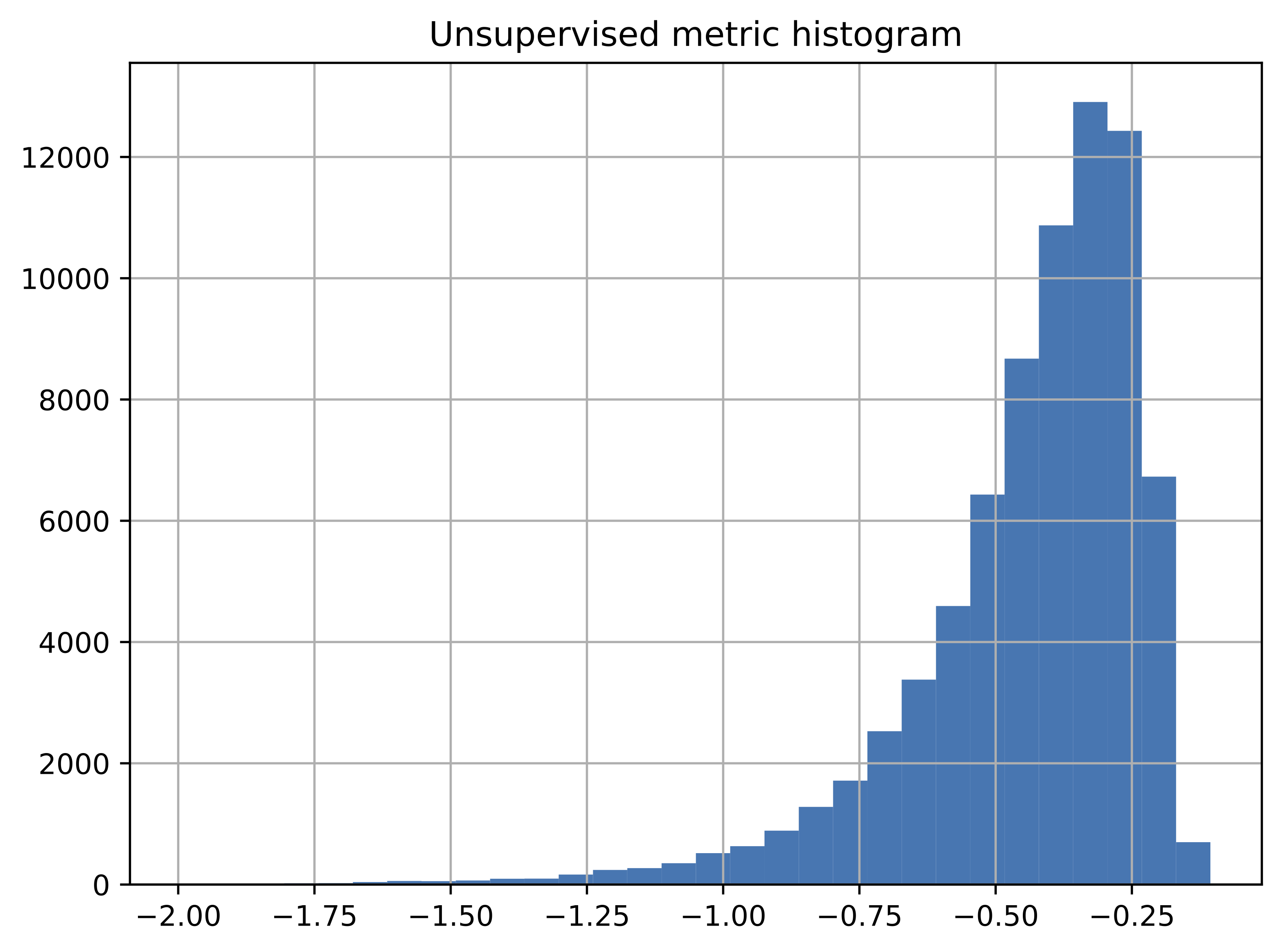
We see that the unsupervised metric is closely correlated with the BLEU2VEC supervised metric. Although they are not always aligned, the metric can be very useful when no ground truth data is available. The histograms illustrate the correlation between the two metrics.
The unsupervised metric is ranged between -5 and 0. Larges values indicate larger probability of a good translation.
We have used an unsupervised approach to QE where no training or access to any additional resources besides the MT system is required. Besides exploiting softmax output probability distribution and the entropy of attention weights from the NMT model, we leverage uncertainty quantification for unsupervised QE. We show that the indicators extracted from the NMT system constitute a rich source of information, competitive with supervised QE methods.