Pipeline
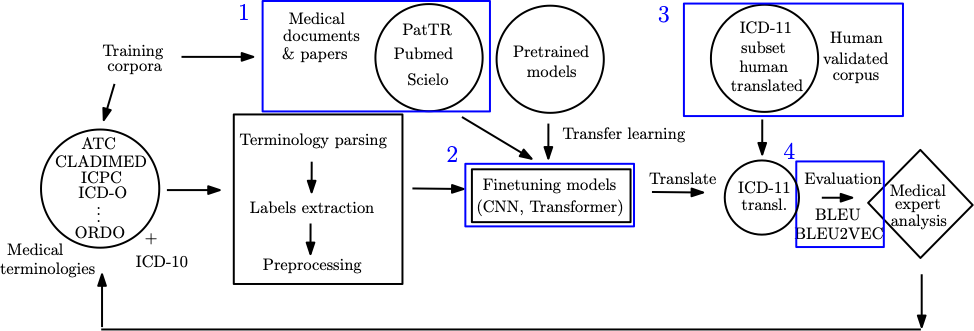
An abstractive illustration of our proposed methodology is shown in Figure 1. Essentially, the pipeline can be split in five major parts:
dataset & terminologies’ search and retrieval,
parsing, extraction, preprocessing and extracting ground truth data,
model training,
translation and inspection, and
evaluation and expert analysis.
More specifically, having access to the aforementioned datasets, we first applied terminology parsing. Next, we extracted the labels or descriptions, in order to form the corpus of parallel sentences. During the pre-processing step, we need to prepare the data for training the translation systems and perform tokenization, true-casing and cleaning. For the NMT models, the BPE process is applied. The automatic translation evaluation is based on the correspondence between the output and reference translation (ground truth/gold standard). We use popular metrics that we present in the following subsections. Apart from traditional pre-processing or post-processing techniques we may also apply some transformation rules on the training datasets or output. We will refer to this process as configuration rules, and we will describe it in detail in the next subsection.