Training
Training methodology schema
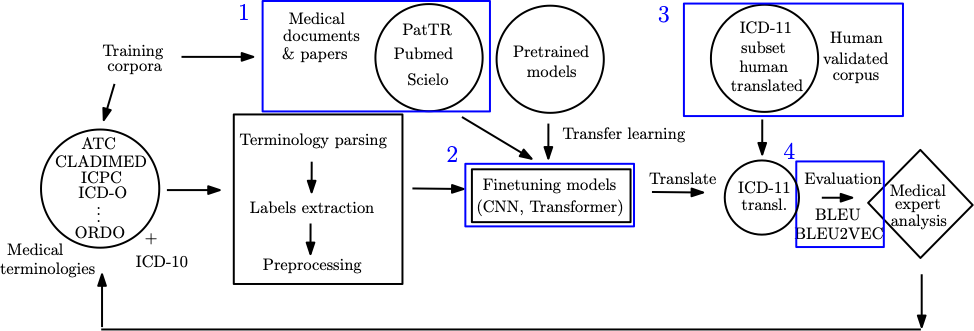
An abstractive illustration of the original training methodology is shown above. This schema describes the research workflow used to prepare and evaluate translation models before they are served by the Docker application. The workflow can be split into five major parts:
dataset and terminology search and retrieval;
parsing, extraction, preprocessing, and extraction of ground-truth data;
model training;
translation and inspection;
evaluation and expert analysis.
More specifically, after collecting the terminology datasets, terminology parsing is applied. Labels or descriptions are extracted to form the corpus of parallel sentences. During preprocessing, the data is prepared for training the translation systems with tokenization, true-casing, cleaning, and, for NMT models, BPE processing.
Automatic translation evaluation is based on the correspondence between model output and the reference translation, also called ground truth or gold standard. Traditional preprocessing and postprocessing techniques can also be combined with configuration rules applied to the training datasets or to model output.
Fine-tuning script
A pre-trained model is utilized (which is trained on a large general textual corpus) and then we fine-tune (continue training) on a specialized dataset, in our case medical terminologies. For the pre-trained model, we select NLLB (facebook/nllb-200-distilled-600M). Next, we show the training script we use:
import torch
from datasets import Dataset
from transformers import (
AutoModelForSeq2SeqLM,
AutoTokenizer,
Seq2SeqTrainingArguments,
Seq2SeqTrainer,
DataCollatorForSeq2Seq,
)
import evaluate
import numpy as np
import os
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
torch.cuda.empty_cache()
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
torch.set_float32_matmul_precision("high")
# --- Configuration ---
MODEL_CHECKPOINT = "facebook/nllb-200-distilled-600M"
# MODEL_CHECKPOINT = "facebook/nllb-200-1.3B"
SOURCE_LANG = "eng_Latn" # NLLB code for English
TARGET_LANG = "fra_Latn" # NLLB code for French
# Replace these with your actual file paths
# SRC_FILE_PATH = "data/medterms_plus_snomed.en"
# TGT_FILE_PATH = "data/medterms_plus_snomed.fr"
# OUTPUT_DIR = "./nllb-medical-en-fr_SNOMED"
SRC_FILE_PATH = "data/initial_unique_english.txt"
TGT_FILE_PATH = "data/initial_unique_french.txt"
OUTPUT_DIR = "./nllb-medical-en-fr_INITIAL"
def load_data_from_files(src_path, tgt_path):
"""
Reads two line-aligned files and converts them into a Hugging Face Dataset.
"""
with open(src_path, "r", encoding="utf-8") as f_src, \
open(tgt_path, "r", encoding="utf-8") as f_tgt:
src_lines = [line.strip() for line in f_src if line.strip()]
tgt_lines = [line.strip() for line in f_tgt if line.strip()]
if len(src_lines) != len(tgt_lines):
raise ValueError(f"Mismatch in line counts! Source: {len(src_lines)}, Target: {len(tgt_lines)}")
data = [{"translation": {SOURCE_LANG: s, TARGET_LANG: t}} for s, t in zip(src_lines, tgt_lines)]
return Dataset.from_list(data)
def main():
# 1. Load and Split Data
print("Loading data...")
dataset = load_data_from_files(SRC_FILE_PATH, TGT_FILE_PATH)
# Split into train and validation (90% train, 10% validation)
dataset = dataset.train_test_split(test_size=0.1)
# 2. Initialize Tokenizer
tokenizer = AutoTokenizer.from_pretrained(
MODEL_CHECKPOINT,
src_lang=SOURCE_LANG,
tgt_lang=TARGET_LANG
)
# 3. Preprocessing Function
max_input_length = 128
max_target_length = 128
def preprocess_function(examples):
inputs = [ex[SOURCE_LANG] for ex in examples["translation"]]
targets = [ex[TARGET_LANG] for ex in examples["translation"]]
# Tokenize inputs
model_inputs = tokenizer(
inputs,
max_length=max_input_length,
truncation=True
)
# Tokenize targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(
targets,
max_length=max_target_length,
truncation=True
)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
print("Tokenizing data...")
tokenized_datasets = dataset.map(preprocess_function, batched=True)
# 4. Load Model
model = AutoModelForSeq2SeqLM.from_pretrained(MODEL_CHECKPOINT, attn_implementation="sdpa")
model.config.use_cache = False
# 5. Define Metric (SacreBLEU)
metric = evaluate.load("sacrebleu")
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Post-processing for SacreBLEU
decoded_preds = [pred.strip() for pred in decoded_preds]
decoded_labels = [[label.strip()] for label in decoded_labels]
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
return {"bleu": result["score"]}
# 6. Training Arguments
args = Seq2SeqTrainingArguments(
output_dir=OUTPUT_DIR,
eval_strategy="no",
save_strategy="steps",
save_steps=1000,
logging_steps=100,
learning_rate=3e-5, # Slightly higher LR is okay for smaller models
# FIX 3: Lower batch size for stability, use accumulation for speed
per_device_train_batch_size=12, # Low and steady
gradient_accumulation_steps=8, # Total batch still 32
per_device_eval_batch_size=4,
# FIX 4: Optimization for Windows/3090
dataloader_num_workers=0, # DO NOT use > 0 on Windows for this task
group_by_length=False, # Disable this to prevent memory spikes
fp16=True,
predict_with_generate=False,
weight_decay=0.01,
num_train_epochs=1,
optim="adamw_torch_fused",
)
# 7. Data Collator
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=-100 # Ignore padding in loss calculation
)
# 8. Trainer
trainer = Seq2SeqTrainer(
model=model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
# 9. Train
print("Starting training...")
trainer.train()
# 10. Save the final model
print(f"Saving model to {OUTPUT_DIR}")
trainer.save_model(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)
if __name__ == "__main__":
main()
Loss and Stopping Criteria
The script uses the default sequence-to-sequence training objective from Seq2SeqTrainer:
Token-level cross-entropy loss over decoder outputs.
Padding tokens are excluded from loss with
label_pad_token_id=-100inDataCollatorForSeq2Seq.No label smoothing is configured in
Seq2SeqTrainingArguments(default behavior).
Training stop condition in this configuration:
Fixed-duration training with
num_train_epochs=1.No early stopping callback is used.
Checkpoints are saved every
save_steps=1000, but stopping is controlled by the epoch limit.